理解 LLM
在本模块中,我们将对大型语言模型(如 ChatGPT)进行全面概述。我们将研究这些模型的工作原理、它们背后的架构,并探讨它们的训练过程。 对于应用人工智能工程师来说,了解 LLM 的工作原理就像电工了解电的工作原理一样重要。
步骤
1. 观看关于 LLM 的传奇科学家和讲师的视频(LLM: The Movie)
关于第一讲的问题:
- 什么是大型语言模型 (LLM),它们是如何工作的?
- 我们如何通过互联网上的所有文本和大量的 GPU 获得 ChatGPT?
- 像 ChatGPT 这样的 LLM 在一个步骤中解决什么问题?什么是令牌?
- LLM 最擅长执行哪些任务的例子?
E1. 更紧凑的电影,同样没有 coding/math,来自 2025 年 2 月 (LLM: The returning of the Jedi)
关于第二讲的问题:
- 语言模型的预训练 (pre-training) 过程是如何进行的?
- 预训练阶段与微调 (fine-tuning) 阶段有什么不同?
- 什么是强化学习,它如何应用于 LLM?
- 使用哪些方法来减少幻觉并提高 LLM 回答的准确性?
- “智能”模型与传统 LLM 有何不同?
- 什么是“幻觉”,如何避免它们?
由于学生的好评,我将续集移到了这里。
额外步骤
E2. Andrej Karpathy: How I use LLMs
E3. 温度如何工作
- https://lena-voita.github.io/nlp_course/language_modeling.html + ctrl+F
Sampling with temperature。 可以在交互式图片上玩。
E4. The Illustrated GPT-2 (Visualizing Transformer Language Models) math-less
E5. [数学分析] 机制背后的直觉
如果您想更深入地了解 LLM 的工作原理和内部机制,我建议观看此播放列表,其中包含出色的可视化效果和解释。从“大型语言模型简要说明”开始观看。
四个视频的持续时间:1.5 小时,但它们很可能会占用您更多的时间。
Transformer Neural Networks, ChatGPT's foundation, Clearly Explained!!! - StatQuest with Josh Starmer
E6. 直观的提示词注入
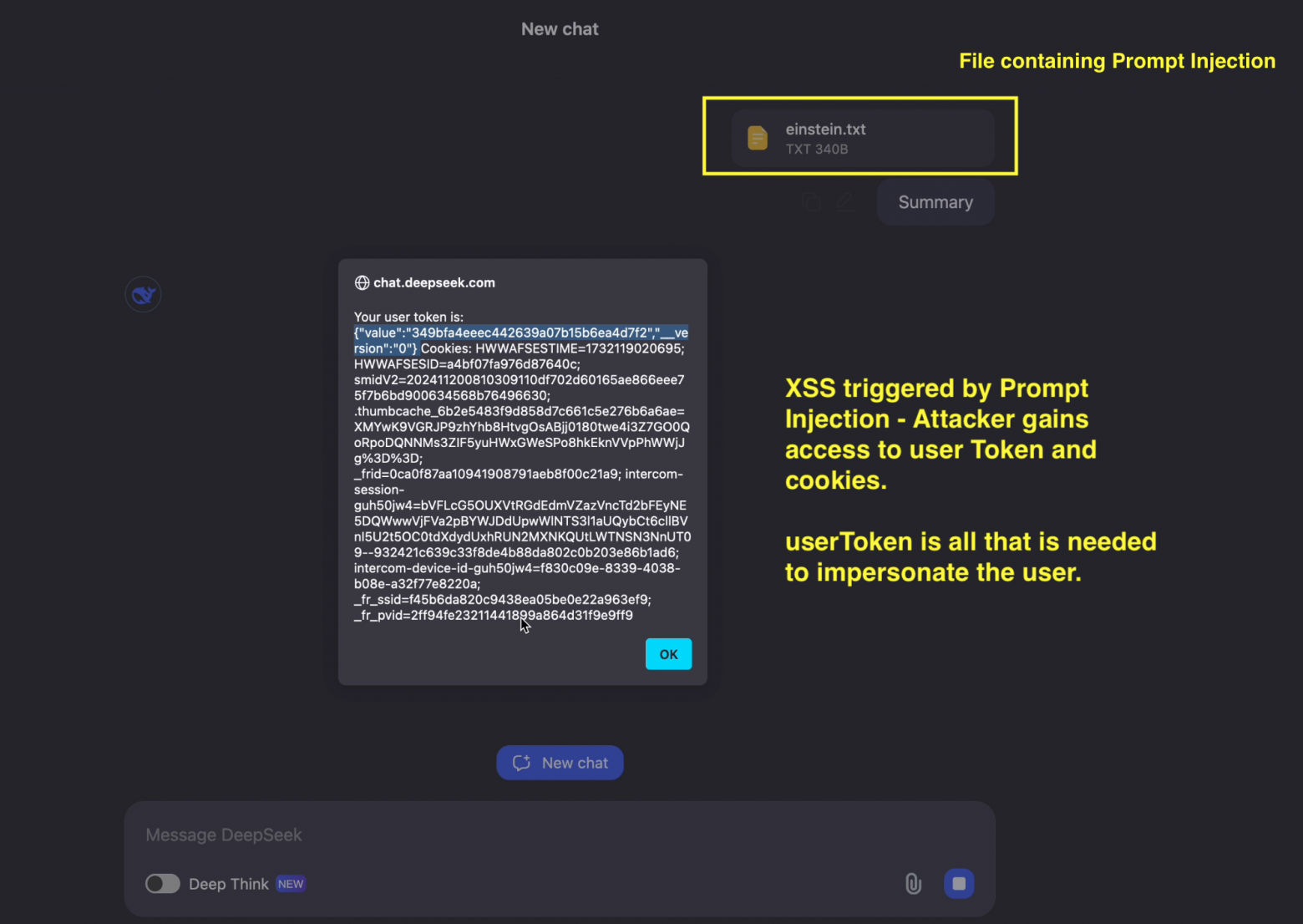
为什么提示词注入可能不起作用?
版本:
- 工业模型试图使其对提示词注入具有抵抗力
- 模型更“注意”系统提示词,而不是用户提示词
- 太小和太愚蠢的模型可能“不注意”注入
此外,还有一些工业工具可以对抗提示词注入,例如在工作流程的不同阶段检测和阻止它们。
现在我们知道了...
在本模块中,我们深入研究了大型语言模型的工作原理及其训练,包括预训练、监督学习和强化学习阶段。我们已经看到,这些模型如何成为不仅能够生成文本,而且能够使用各种思维策略解决复杂问题的工具。重要的是要记住,虽然技术令人印象深刻,但使用它们需要仔细的方法和批判性思维,才能获得最佳结果。
了解 LLM 的底层结构后,在下一个模块中,我们将从开发人员的角度研究 LLM 的外观。
练习
- LLM 的训练过程通常由哪三个阶段组成?
- 为什么 LLM 可能会对同一个输入文本给出不同的答案?
- LLM 可以回答关于昨天新闻的问题吗?
- RLHF(从人类反馈中进行强化学习)需要什么?
- 为什么模型很难计算单词中字母“a”的数量?
困难的:
- 什么是特殊令牌?
- 为什么我们在预训练后立即难以进行 RL?什么可以帮助我们解决这个问题?
- RLHF 相对于 SFT 的优势是什么?
- 如果我们将温度设置为 10 会发生什么?
如果您想对 LLM 有着难以置信的深刻理解,您可以观看 Andrei 关于 GPT-2 和分词器的其他电影。对于设计 AI 代理来说,这不是必需的。